반응형
데이터에 대한 이해
과학 기술의 정립 과정

- 예) Tycho Brache 는 천동설이라는 틀린 모델을 선택하여 수집한 데이터를 설명하지 못함
- Johannes Kepler는 지동설 모델을 도입하여 제 1, 제 2, 제 3법칙을 완성함.
기계학습
- 기계학습은 복잡 문제/과업을 다룸
- 지능적 범주의 행위들은규칙의 다양한 변화 양상을 가짐
- 단순한 수학 공식으로 표현 불가능함
- 데이터를 설명할 수 있는 학습 모델을 찾아내는 과정

→ 과학기술과 기계학습은 비슷한 모습을 보인다.
→ 과학기술이라고 하는 것 자체는 수학적인 공식에 의해서 표현을 한다. 하지만 기계학습이나 데이터과학이라고 하는 분야는 단순한 수학 모델에 의해 표현이 불가능하며, 규칙을 찾는다던지 학습을 통해서 해결을 하려고 하는 과정이다.
→ 기계학습이라고 하는 것 자체는 데이타를 기반으로해서 어떤 가설을 만들어 낸 다음, 그 가설에서 나온 값이 실제 측정값과의 차이(목적함수)가 최소한의 값을 가지도록 매개변수에 대한 값을 찾은 후, 이 찾아진 값을 가지고 학습된 모델을 정의해서 예측을 수행 하는 것이다.
→ 데이터라고 하는 것은 인위적으로 생기지 않는다, 눈에는 보이지 않고 설명할 수 없지만. 내제되어있는 규칙에 의해 발현된다. 데이터를 많이 수집할 수록 규칙에 대한 이해도가 높아진다.
데이터 생성 과정
데이터 생성 과정을 완전히 아는 인위적 상황의 에제 (가상)
- 예) 두 개 주사위를 던져 나온 눈의 합을 x라 할 때, y=(x+7)^2 +1 점을 받는 게임
- 해당 상황은 '데이터 생서 과정을 완전히 알고 있다'고 말함
- x를 알면 정확히 y를 예측할 수 있음
- → 실제 주사위를 던져 X = [3,10,8,5]를 얻었다면, Y=[17,10,2,5]
- x의 발생확률 P(x)를 정확히 알 수 있음
- P(x)를 알고 있으므로, 새로운 데이터 생성 가능

→ 완벽히 통제 가능하고 생성가능한 상황이다. 수학적 모델링에 의해 모든 규칙들이 설명이 가능하기 때문에 기계학습에서는 다루지 않으며 확률 통계적 측면에서 다룬다.
실제 기계 학습 문제 (현실)
- 데이터 생성 과정을 알 수 없음
- 단지 주어진 훈련집합의 X,Y로 가설 모델을 통해 근사 추정만 가능

→ 기계학습에서는 우리는 다루려고 하는 데이터 집합들의 규칙을 모른다. 규칙을 알 수 없지만 규칙이 존재한다는 것은 명확하다. 이 규칙은 수학적으로 정의되지 않으며 이 규칙에 의해 발현되는 경험들을 학습한 모델을 통해서 근사추정만 가능하다.
데이터의 중요성
데이터의 양과 질
- 주어진 과업에 적합한 다양한 데이터를 충분한 양만큼 수집 → 과업 성능 향상
- 예) 정면 얼굴만 가진 데이터로 인식 학습하면,→ 주어진 과업에 관련된 데이터 확보는 아주 중요함
- 측면 얼굴은 매우 낮은 인식 성능을 가짐
- 데이터 양과 학습 모델의 성능 경향성 비교
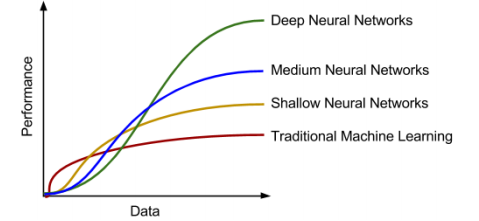
공개 데이터
- 기계 학습의 대표적인 3가지 데이터 : Iris, MNIST, ImageNet
- UCI 저장소 (2017년 11월 기준으로 394개 데이터 제공)
→ 매개변수가 적을 수록, 클래식한 머신러닝이며 신경망의 영역으로 갈수록 매개변수 수가 증가한다.
→ 매개변수 수가 증가하는 것은 모델의 용량이 증가하는 것이며, 표현능력이 커지는 것을 말한다.
→ 데이터가 적을 수록 클래식한 머신러닝이 좋은 성능을 보인다. 결정해야할 매개변수가 적어도 충분한 성능을 내보일 수 있기 때문이다. 반면 용량이 큰 모델 같은 경우 성능이 낮아진다. 많은 매개변수들을 임의의 값으로 부터 시작해서 다 찾아야하기 때문이다. 데이터가 충분히 보장되는 경우에는 딥러닝의 모델 용량도 보장이되고, 그에 의해 매개변수도 다 결정이 되기 때문에 훨씬 더 좋은 성능을 낼 수 있다.
→ 내가 가지고 있는 데이터를 설명할 수 잇는 모델의 용량이 낮으면, 그 안에 가변적으로 변할 수 있는 설명가능한 범주가 작아진다.
→ 데이터는 실제 딥러닝, 인공지능에 직접적인 영향을 주는 중요한 매개변수이다. 데이터가 많으면 많을 수록 성능이 좋다.
데이터베이스 크기와 기계 학습 성능
데이터의 적은 양 → 차원의 저주와 관련
예) MNIST: 28*28 단순히 흑백으로 구성된다면 서로 다른 총 샘플 수는 2^784가지이지만, MNIST는 고작 6만 개 샘플

적은 양의 데이터베이스로 어떻게 높은 성능을 달성하는가?
방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분 공간임
→ 데이터의 희소 특성 가정- 다음과 같은 데이터 발생 확률은 거의 0 가까움

- 다음과 같은 데이터 발생 확률은 거의 0 가까움
매니폴드 (많이 + 끼다) 가정
- 매니폴드 가정이란, 데이터는 고차원으로 이루어져있지만, 이들의 집합을 포함하는 저차원의 SubSpace(Manifold) 를 만들 수 있다는 것
- Manifold 는 고차원의 데이터를 저차원으로 옮길 때, 데이터를 잘 설명하는 집합의 모형
- 즉, MNIST 숫자들은 내재되어 있는 규칙을 가지고 있기 때문에, 고차원에서의 규칙이 저차원에서 유사하게 보존됨
- 사실, MNIST 이미지(28*28) 에서 실제로 의미있는 부분은 일부분(숫자가 적힌 부분)임
- 즉, 784 차원에서 일부 차원만 유의미한 값을 가지고 있음
- 따라서, MNIST 이미지는 전체 차원의 크기와 상관 없이, 고차원에서의 규칙이 저차원에서 유사하게 보존되므로, 60000 개의 이미지로도 좋은 성능을 낼 수 있음
- 일정한 규칙에 따라 매끄럽게 변화

- 매니폴드 가정이란, 데이터는 고차원으로 이루어져있지만, 이들의 집합을 포함하는 저차원의 SubSpace(Manifold) 를 만들 수 있다는 것
데이터 가시화
- 4차원 이상의 초공간은 한꺼번에 가시화 불가능
- 여러 가지 가시화 기법
- 2개씩 조합하여 여러 개의 그래프 그림

→ 4차원 이상의 데이터를 다루는 경우에는 2차원 2차원씩 조합을 만들어서 시각화를 하거나 고차원의 데이터를 저차원으로 투영시켜야한다. 이를 통해서 고차원에 있는 특징들이 저차원에서도 (매니폴드 관점에서도) 보존이 되어야한다.
- 2개씩 조합하여 여러 개의 그래프 그림
참고
반응형
'Artificial intelligence' 카테고리의 다른 글
| [AI] 기계 학습 유형 (0) | 2021.09.10 |
|---|---|
| [AI] Convex Optimization (볼록 최적화) / Convex, Non-Convex (0) | 2021.09.08 |
| [AI] 선형 회귀 문제와 매개변수 최적화 관계 (0) | 2021.09.08 |
| [AI] 인공지능과 특징공간 / 표현학습과 심층학습 (0) | 2021.09.07 |
| [AI] 인공지능과 기계학습 (0) | 2021.09.07 |



