반응형
K-최근접 이웃(K-Nearest Neighbor, KNN)
- 지도 학습 알고리즘 중 하나로 어떤 데이터가 주어지면 그 주변의 데이터를 살펴본 뒤 더 많은 데이터가 포함되어 있는 범주로 분류하는 방식이다.
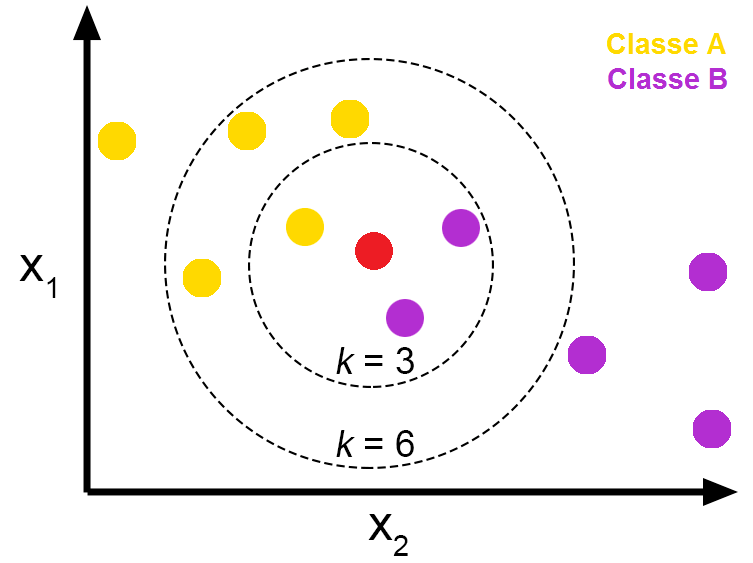
- 새로운 데이터 (빨간 점)을 Class A / Class B 로 분류해보자.
- k =3
- 가까운 주변의 데이터 3개를 본다.
- 빨간 점 주변에 노란색 점(Class A) 1개와 보라색 점(Class B) 2개가 있다.
- 새로운 데이터 (빨간 점) 는 Class B (보라색 점) 으로 분류된다.
- k =6
- 가까운 주변의 데이터 3개를 본다.
- 빨간 점 주변에 노란색 점(Class A) 4개와 보라색 점(Class B) 2개가 있다.
- 새로운 데이터 (빨간 점) 는 Class A (노란색 점) 으로 분류된다.
- k =3
- K 의 default 값은 5이다.
- 일반적으로 K는 홀수를 사용한다. 짝수일 경우 동점이 되면 결과를 도출할 수 없기 때문이다.
Iris 데이터셋을 사용하여 KNN 분류하기
- 붓꽃(iris) 데이터 세트
- 다중 클래스 분류 대표 예제이다.
- 꽃잎(petal)의 길이와 너비, 꽃받침(sepal)의 길이와 너비를 기반으로 꽃의 품종(setosam, vesicolor, virginca)을 예측한다.
from sklearn.datasets import load_iris
iris_dataset = load_iris()- sklearn.datasets 내의 모듈은 사이킷런에서 자체적으로 제공하는 데이터 세트를 생성하는 모듈의 모임이다.
- 붓꽃 데이터 세트는 scikit-learn의 datasets 모듈에 포함되어 있다.
- load_iris( )를 이용하여 붓꽃 데이터 세트를 생성한다.
- load_iris가 반환한 iris 객체는 파이썬의 딕셔너리 Dictionary 와 유사한 Bunch 클래스의 객체이다.
In[1]
print("iris_dataset's key \n{}".format(iris_dataset.keys()))Out[1]
iris_dataset's key
dict_keys(['data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename'])In[2]
import pandas as pd
iris_df = pd.DataFrame(data = iris_dataset.data, columns = iris_dataset.feature_names)
iris_df['label'] = iris_dataset.target
iris_df.head(3)- 붓꽃 데이터 세트를 자세히 보기 위해 DataFrame으로 변환한다.
Out[2]

- 특성(feature_names)에는 sepal length, sepal width, petal length, petal width가 있다. (sepal: 꽃받침, petal: 꽃잎)
- 레이블(Label, 결정값)은 0, 1, 2 세 가지 값으로 되어 있으며 0: Setosa, 1: vesicolor, 2: virginca 품종을 의미한다.
- 테이블을 보면 품종에 따른 꽃잎과 꽃받침의 길이와 폭을 확인할 수 있다.
훈련 데이터와 테스트 데이터
- 모델을 만든 후 새 데이터에 적용하기 전에 우리가 만든 모델의 예측을 신뢰할 수 있는지 알아야 한다.
- 모델을 만들때 사용한 데이터는 성과 측정의 목적으로 사용할 수 없다. (모델이 훈련 데이터를 전부 기억할 수 있기 때문)
- 모델의 성능을 측정하려면 모델을 만들 때 사용한 데이터 외에 이전에 본 적 없는 새 데이터를 모델에 적용해봐야한다. 이를 위해 우리가 가진 레이블된 데이터를 두 그룹으로 나눈다.
- 그 중 하나는 머신러닝 모델을 만들 때 사용하며, 훈련 데이터 혹은 훈련 세트 training set 라고 한다.
- 나머지 하나는 모델이 얼마나 잘 작동하는 지 측정하는 데 사용하며, 이를 테스트 데이터, 테스트 세트 test set 혹은 홀드아웃 세트 hold-out set 라고 한다.
- scikit-learn은 데이터셋을 섞어서 나눠주는 train_test_split 함수를 제공한다. 이 함수는 전체 행 중 75% 를 레이블 데이터와 함께 훈련 세트로 뽑는다. 나머지 25%는 레이블 데이터와 함께 테스트 세트가 된다. 훈련 세트와 테스트 세트를 얼만큼씩 나눌지는 상황에 따라 다르지만 전체의 25%를 테스트 세트로 사용하는 것은 일반적으로 좋은 선택이다.
- scikit-learn에서 데이터는 대문자 X로 표시하고 레이블은 소문자 y로 표기한다. 이는 수학에서 함수의 입력을 x, 출력을 y로 나타내는 표준 공식 f(x)=y에서 유래되었다. 수학의 표기 방식을 따르되 데이터는 2차원 배열(행렬)이므로 대문자 X를, 타깃은 1차원 배열(벡터)이므로 소문자 y를 사용한다.
In[3]
print("X_train 크기: {}".format(X_train.shape))
print("y_train 크기: {}".format(y_train.shape))
print("X_test 크기: {}".format(X_test.shape))
print("y_test 크기: {}".format(y_test.shape))Out[3]
X_train 크기: (112, 4)
y_train 크기: (112,)
X_test 크기: (38, 4)
y_test 크기: (38,)데이터 살펴보기
- 컴퓨터 화면은 2차원이기 때문에 한 번에 2개의 특성만 표현이 가능하다. 그러므로 특성을 짝지어 만드는 산점도 행렬을 사용한다.
- 하지만 산점도 행렬은 한 그래프에 모든 특성의 관계가 나타나는 것이 아니기 때문에 각각의 나누어진 산점도 그래프에는 드러나지 않는 중요한 성질이 있을 수도 있다.
In[4]
iris_dataframe = pd.DataFrame(X_train, columns=iris_dataset.feature_names)
pd.plotting.scatter_matrix(iris_dataframe, c=y_train, figsize=(15, 15), marker='o',
hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)Out[4]
- 클래스 레이블을 색으로 구분한 iris 데이터셋의 산점도 행렬이다.
- 그래프를 보면 세 클래스가 꽃잎과 꽃받침의 측정값에 따라 비교적 잘 구분되는 것을 알 수 있다.
- 이 그림의 대각선에 위치한 그래프는 각 특성의 히스토그램이다.
머신러닝 모델 : K-최근점 이웃 알고리즘
- scikit-learn의 분류 알고리즘 중 k-최근접 이웃 (k-Nearest Neighbors, k-NN) 분류기를 사용하고자 한다.
- 이 모델은 단순히 훈련 데이터를 저장하여 만들진다. 새로운 데이터 포인트에 대한 예측이 필요하면 알고리즘은 새 데이터 포인트에서 가장 가까운 훈련 데이터 포인트를 찾는다. 그런 다음 찾은 훈련 데이터의 레이블을 새 데이터 포인트의 레이블로 지정한다.
- k-최근접 이웃 알고리즘에서 k는 가장 가까운 이웃 ‘하나’가 아니라 훈련 데이터에서 새로운 데이터 포인트에 가장 가까운 ‘k개’의 이웃을 찾는다는 뜻이다. 그런 다음 이 이웃들의 클래스 중 빈도가 가장 높은 클래스를 예측값으로 사용한다.
In[5]
from sklearn.neighbors import KNeighborsClassifier
knn = KNeighborsClassifier(n_neighbors=1) # 이웃의 개수를 1로 지정함# 훈련 데이터인 NumPy 배열 X_train과 훈련 데이터의 레이블을 담고 있는 NumPy 배열 y_train을 매개변수로 받아 훈련모델 생성
knn.fit(X_train, y_train)Out[5]
KNeighborsClassifier(algorithm='auto', leaf_size=30, metric='minkowski',
metric_params=None, n_jobs=1, n_neighbors=1, p=2,
weights='uniform')- fit 메서드는 knn 객체 자체를 반환한다.(그리고 knn 객체 자체를 변경시킵니다). 그러므로 knn 객체가 문자열 형태로 출력된다.
예측하기
- 이제 이 모델을 사용해서 정확한 레이블을 모르는 새 데이터에 대해 예측을 만들 수 있다.
In[6]
# 꽃받침의 길이가 5cm, 폭이 2.9cm이고 꽃잎의 길이가 1cm, 폭이 0.2cm인 붓꽃 데이터 생성
X_new = np.array([[5, 2.9, 1, 0.2]])
print("X_new.shape: {}".format(X_new.shape))Out[6]
X_new.shape: (1, 4)In[7]
prediction = knn.predict(X_new)
print("예측: {}".format(prediction))
print("예측한 타깃의 이름: {}".format(
iris_dataset['target_names'][prediction]))Out[7]
- 모델은 새로운 붓꽃을 setosa 품종을 의미하는 클래스 0으로 예측한다.
예측: [0]
예측한 타깃의 이름: ['setosa']
모델 평가하기
- 앞에서 만든 테스트 데이터를 사용한다. 이 데이터는 모델을 만들 때 사용하지 않았고 테스트 세트에 있는 각 붓꽃의 품종을 정확히 알고 있다.
- 따라서 테스트 데이터에 있는 붓꽃의 품종을 예측하고 실제 레이블(품종)과 비교할 수 있다. 얼마나 많은 붓꽃 품종이 정확히 맞았는지 정확도를 계산하여 모델의 성능을 평가한다.
In[8]
y_pred = knn.predict(X_test)
print("테스트 세트에 대한 예측값:\n {}".format(y_pred))Out[8]
테스트 세트에 대한 예측값:
[2 1 0 2 0 2 0 1 1 1 2 1 1 1 1 0 1 1 0 0 2 1 0 0 2 0 0 1 1 0 2 1 0 2 2 1 0 2]In[9]
print("테스트 세트의 정확도: {:.2f}".format(np.mean(y_pred == y_test)))Out[9]
테스트 세트의 정확도: 0.97- Knn객체의 score메서드로도 테스트 세트의 정확도를 계산할 수 있다.
In[10]
print("테스트 세트의 정확도: {:.2f}".format(knn.score(X_test, y_test)))Out[10]
테스트 세트의 정확도: 0.97- 이 모델의 테스트 세트에 대한 정확도는 약 0.97이다. 이 말은 테스트 세트에 포함된 붓꽃 중 97%의 품종을 정확히 맞혔다는 뜻이다.
참조
반응형
'Artificial intelligence' 카테고리의 다른 글
| [AI] torchvision AlexNet, VGG16, ResNet18, DenseNet121 에 대한 성능 비교하기 (0) | 2021.12.16 |
|---|---|
| [AI] 평균 제곱 오차(MSE), 교차 엔트로피 오차(CEO), 로그우도(NLL) 계산 방법 (0) | 2021.12.03 |
| [AI] 다층 퍼셉트론 - 특징공간 변환 (XOR 분류 테스트) (0) | 2021.10.27 |
| [AI] 단층 퍼셉트론 (Single-layer Perceptron) (0) | 2021.09.23 |
| [AI] 검증집합과 교차검증을 이용한 모델 선택 알고리즘 / 데이터 확대와 가중치 감쇠 (2) | 2021.09.11 |



